# Data Science
## What is Data Science?
**Data science** is the field of study that explores vast volumes of **information** using cutting-edge tools and techniques to discover concealed **patterns**, extract valuable **insights**, and formulate **business decisions** based on that knowledge. **Predictive models** are constructed using sophisticated **machine learning algorithms** in data science. The **data** utilized for analysis can originate from diverse **sources** and be presented in various **formats**.
## What is a Data Science Life Cycle?
The **Data Science Life Cycle** refers to the step-by-step process involved in solving real-world problems and extracting meaningful insights from data using data science methodologies. It encompasses a series of stages that guide data scientists and analysts throughout the entire data-driven project, ensuring a systematic and organized approach to data analysis and decision-making.
Several processes are taken during the entire process, including data preparation, cleaning, modeling, and model evaluation. The process is lengthy and could take several months to finish. Let's delve into more details of each stage of the Data Science Life Cycle, including the tools commonly used and an example illustrating the application of each stage:
1. **Problem Understanding**:
* **Importance**: Defining the problem clearly is essential as it sets the direction for the entire project. Understanding the business problem helps data scientists determine the appropriate data to collect and the relevant techniques to apply.
* **Tools**: Meetings and discussions with domain experts and stakeholders to gather requirements and expectations.
* **Example**: An e-commerce company wants to reduce customer churn. The data science team identifies the problem as predicting customer churn based on historical user activity.
2. **Data Preparation**:
* **Importance**: Data preparation ensures data is in a usable format, free from errors and inconsistencies. It involves data cleaning, integration, and transformation.
* **Tools**: Python libraries like Pandas and NumPy for data manipulation, cleaning, and preprocessing.
* **Example**: The data science team collects user behavior data, such as purchase history, website visits, and customer demographics. They clean the data, handle missing values, and merge it into a comprehensive dataset.
3. **Exploratory Data Analysis (EDA)**:
* **Importance**: EDA helps data scientists gain insights into the data, identify patterns, correlations, and outliers, which informs subsequent analysis.
* **Tools**: Data visualization libraries like Matplotlib and Seaborn, statistical analysis tools like SciPy.
* **Example**: The team visualizes the data to understand the distribution of customer demographics, purchase frequency, and any correlations between customer activity and churn.
4. **Modeling the Data**:
* **Importance**: Building models is at the heart of data science. The goal is to develop predictive or descriptive algorithms that address the problem defined earlier.
* **Tools**: Machine learning libraries like Scikit-learn, TensorFlow, and Keras for building models.
* **Example**: The data science team uses historical customer data to build a predictive churn model, employing techniques like logistic regression, decision trees, or neural networks.
5. **Evaluating the Model**:
* **Importance**: Model evaluation is crucial to assess its performance and generalization ability. This step helps select the best-performing model for deployment.
* **Tools**: Performance metrics like accuracy, precision, recall, F1-score, and confusion matrices.
* **Example**: The team evaluates the churn prediction model using a test dataset, calculating accuracy, precision, and recall to gauge its effectiveness.
6. **Deploying the Model**:
* **Importance**: Model deployment involves integrating the model into a production environment, where it can be used for making predictions in real-time.
* **Tools**: Web frameworks like Flask or Django for building APIs to serve the model, cloud platforms for hosting.
* **Example**: The churn prediction model is deployed as an API on the company's server, where it can receive new customer data and provide churn predictions.
**Example Summary**: The e-commerce company follows the Data Science Life Cycle to reduce customer churn. The data science team collects, cleans, and explores historical user behavior data. They build a predictive churn model using machine learning techniques and evaluate its performance. Once the best model is selected, it is deployed as an API to predict customer churn in real-time, enabling the company to take proactive measures to retain customers.
> Note that the tools used in each stage may vary depending on the specific project, preferences of the data science team, and the nature of the data being analyzed. The data science ecosystem is vast and continually evolving, with new tools and libraries being developed regularly.
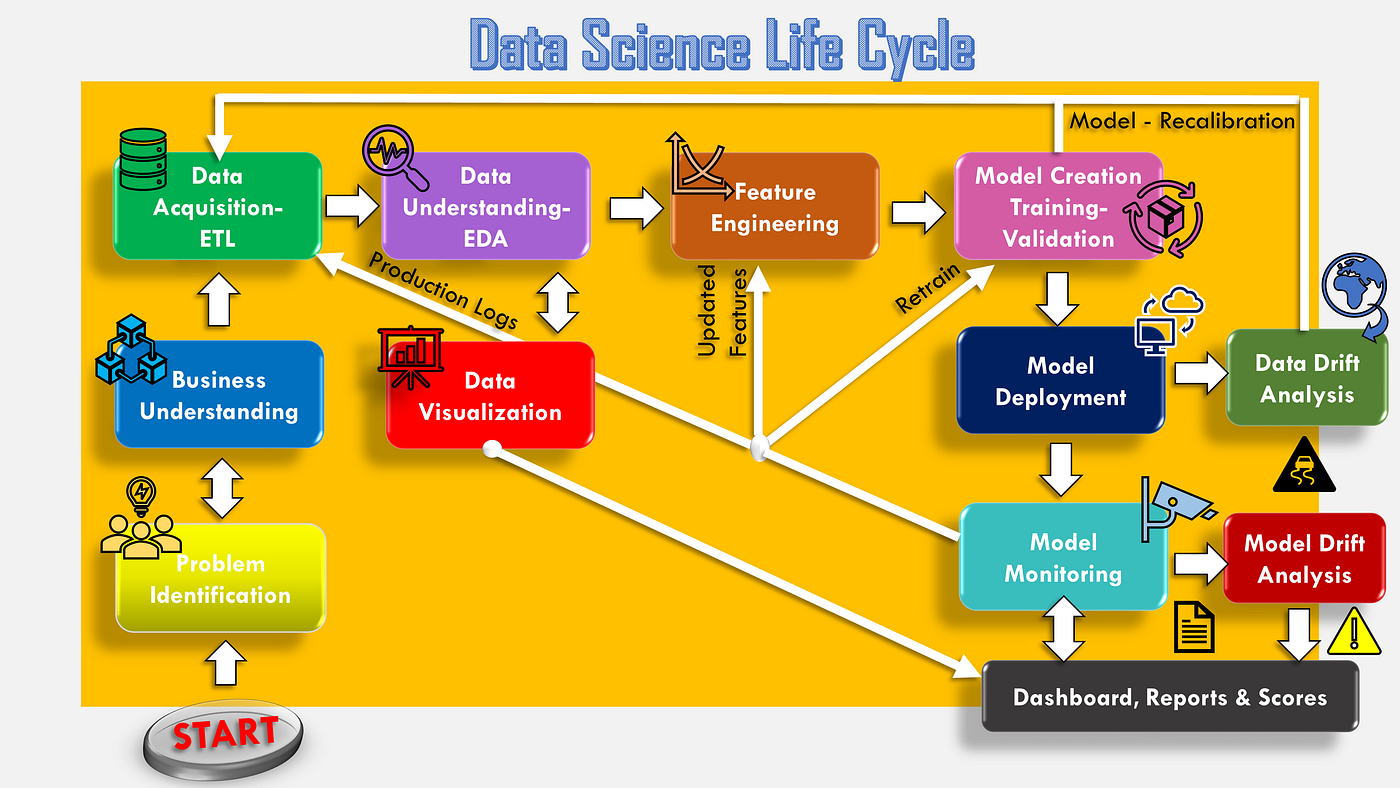
## Data Science Life Cycle
The life cycle of data science contains the following steps:
Data Science life cycle (Sivaraj, 2020)
### Understanding the Business problem
The "why" question served as the catalyst for many world advances.
Every good business or IT-focused life cycle begins with "why," and the same is true for good data science life cycles. The business objective must be clearly understood because it will be the analysis's end result.
A crucial aspect of the early stages of data analytics is to look at business trends, develop case studies of related data analytics in other businesses, and conduct market research on the business's industry. These duties are regularly undertaken by stakeholders at this early stage of data analytics. All members of the team evaluate the internal infrastructure, internal resources, the total amount of time required to complete the project, and the technological requirements for the project. Once all of these analyses and evaluations have been completed, the stakeholders begin developing the primary hypothesis on how to resolve all business difficulties based on the current market condition after all of the preliminary analyses and evaluations have been completed.
In short, to define the business problem for the data science project following are the essential points to remember.
* List the issue that needs to be resolved.
* Define the project's potential value.
* Determine the project's risks, taking ethical issues into account.
* Create and distribute a flexible, high-level project plan.
### Preparing the data
The second phase of the data science life cycle is data preparation. This is to prepare the data to understand the business problem and extract information to solve the problem.

* Selecting data related to the problem.
* Combining the data sets, you may integrate the data.
* Clean the data to find the missing values.
* Handle the missing values by removing or imputing them.
* Errors are dealt with by being removed.
* Use the box plots for detecting outliers and handling them.
### Exploratory Data Analysis (EDA)
Before really developing the model, this step entails understanding the solution and the variables that may affect it. To understand data and data features better, we create heat maps, bar graphs, and charting.
We need to keep a few factors in mind when analyzing the data, including checking that the data is accurate and free of duplicates, missing values, and even null values. Additionally, when working on model construction, we need to be sure that we recognize the crucial factors in the data set and eliminate any extraneous noise that can really reduce the accuracy of our conclusions.
70% of the data science project life cycle time is spent on this step. We can extract lots of information with the proper EDA.
### Modeling the data
This is the most important step of the life cycle of data science. This tells a lot about a data science project. This phase is about selecting the right model type, depending on whether the issue is classification, regression, or clustering. Following the selection of the model family, we must carefully select and implement algorithms to be used inside that family.
There are numerous hyperparameters. Therefore, we should determine the model's ideal hyperparameter values. We don't want to overfit. So hyperparameter tuning is important in model building. This hyperparameter tuning makes the model predict correctly.
### Evaluating the model
We built a model in the previous phase. But isn't our model effective? Therefore, we must determine our model's existing status to improve it.
To evaluate the model to understand the model works better. There are two techniques used widely to assess the performance of the model. They are Hold-Out and Cross-Validation used in data science to evaluate models.
**Holdout evaluation** is the process of testing a model with data that is distinct from the data it was trained on. This offers a frank assessment of learning effectiveness.
**Cross-validation** is the process of splitting the data into sets and using them to analyze the performance of the data. In the cross-validation procedure, the initial observation data set is divided into two sets: a training set for the model's training and an independent set for the analyses' evaluation. Both approaches use a test set (unseen by the model) to assess model performance in order to prevent over-fitting.
If the evaluation does not yield a satisfying outcome, we must repeat the modeling procedure in its entirety until the necessary level of metrics is attained.
Metrics that are used to evaluate the models are:
* Classification models:
* Accuracy
* ROC-AUC
* Precision-Recall o Log-Loss
* Regression models:
* MSAE
* MSPE
* R Square
* Adjusted R Square
* Unsupervised Models:
* Mutual Information
* Rand Index
With the help of this step, we choose the right model for our business problem. Based on this step, we create the model best suits our needs.
### Deploying the model
We have reached the end of our life cycle. In this step, the delivery method that will be used to distribute the model to users or another system is created.
For various projects, this step can mean many different things. Getting your model results in a Tableau dashboard might be all that is necessary. or as complicated as growing it to millions of users on the cloud.
Any shortcuts used during the minimally viable model phase are updated to systems fit for production. This phase is typically carried out by team members who are more "engineering-focused," such as data engineers, cloud engineers, machine learning engineers, application developers, and quality assurance engineers.
The many phases of the data science life cycle should be carefully considered. The entire effort is wasted if any step is carried out incorrectly because it will have an impact on the following phase.
For instance, improper data collection will result in information loss and a model that is not perfect. The model won't function effectively if the data is not adequately cleaned. The model will fall short in the real world if it is not adequately examined. Each phase, from business comprehension to model deployment, should receive the appropriate consideration, time, and effort.
[](https://visitorbadge.io/status?path=https%3A%2F%2Fgithub.com%2Fdrshahizan)
---
# Agent Instructions: Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://drshahizan.gitbook.io/eda1/course-content/fundamentals/lifecycle/data-science.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.